生成式人工智能导论¶
6大型语言模型的修炼史,第一阶段:自我学习,积累实力。¶
背景知识:机器怎么学会做文字接龙? 一个语言模型就是一个函数,输入是未完成的句子,输出是下一个token。这个函数是有数十亿个未知参数的函数,有数十亿个未知参数的函数就叫做模型(transformer)。有大量训练资料,机器学习就可以把数十亿的参数找出来,找出参数的过程就叫做训练training。参数找出来以后,使用函数来做文字接龙这件事情就叫做测试testing。
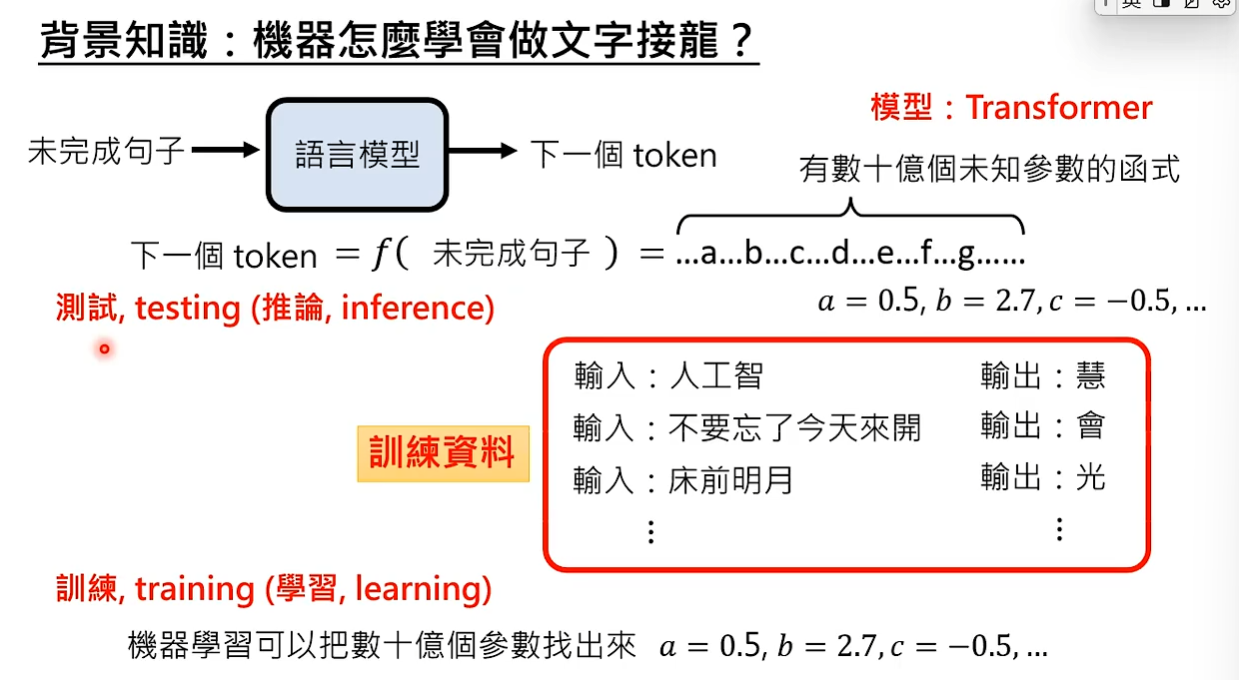
训练的三个阶段都是在做文字接龙,只是训练资料不一样。

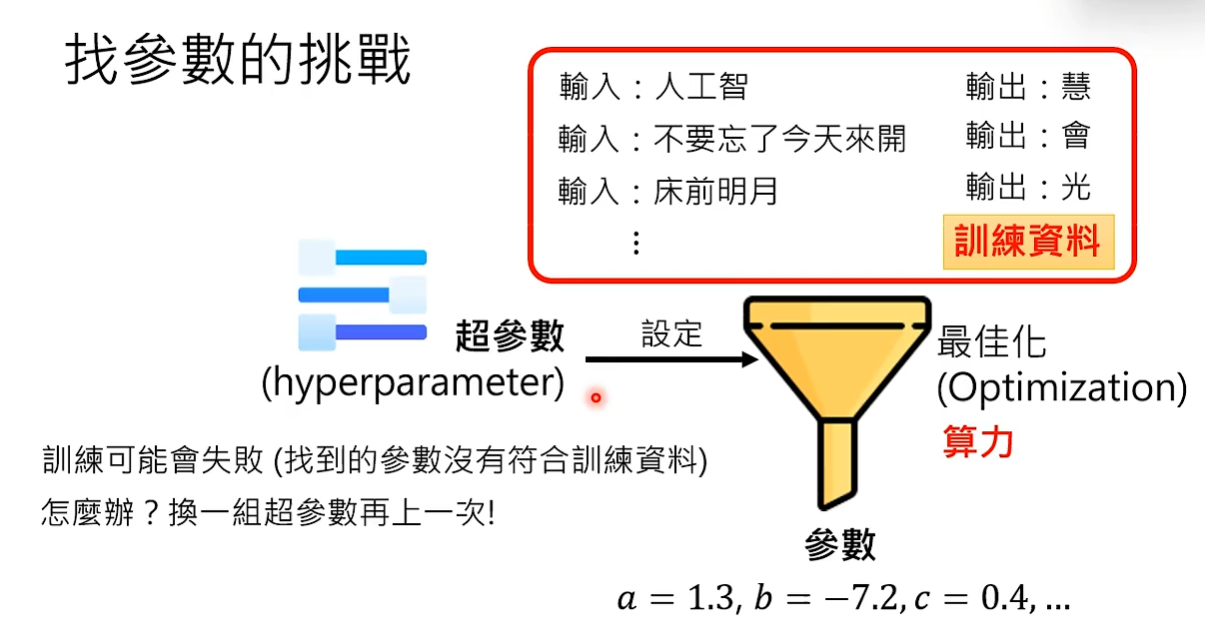
机器学习找出符合训练资料的参数的过程就叫做最佳化。 最佳化是训练过程中的一个具体步骤。最佳化之前需要设定一些参数,设定参数的行为称为超参数,设定超参数以后就决定了最佳化的方法。最佳化方法决定以后,通过训练资料机器学习就可以找出参数。
但是训练是有随机性的,不是每次训练都会成功,训练有可能会失败(没有找出符合训练资料的参数),如果训练失败就换一组超参数重新训练。训练的中间过程非常复杂,有时候一组超参数失败,换一组超参数就能成功。最佳化需要算力,如果训练一直失败,超参数一直换,就需要大量的算力。做机器学习中的“调参数”指的是调超参数。
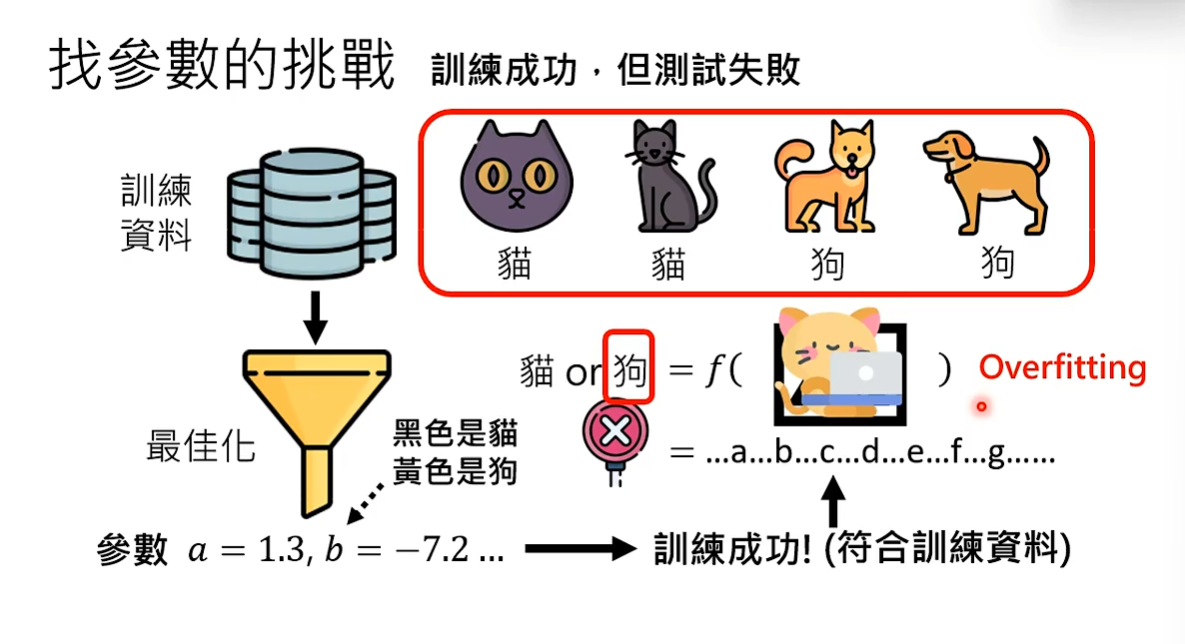
也有可能训练成功,但测试失败。 找到一组参数符合训练资料就代表训练成功,但是重新输入一个训练资料中没有的内容,模型就可能输出错误的结果,这代表测试失败。训练成功但测试失败就叫做Overfitting。机器学习只管找到的参数符不符合训练资料,不管参数是否符合实际情况,因此在训练时要增加训练资料的多样性。
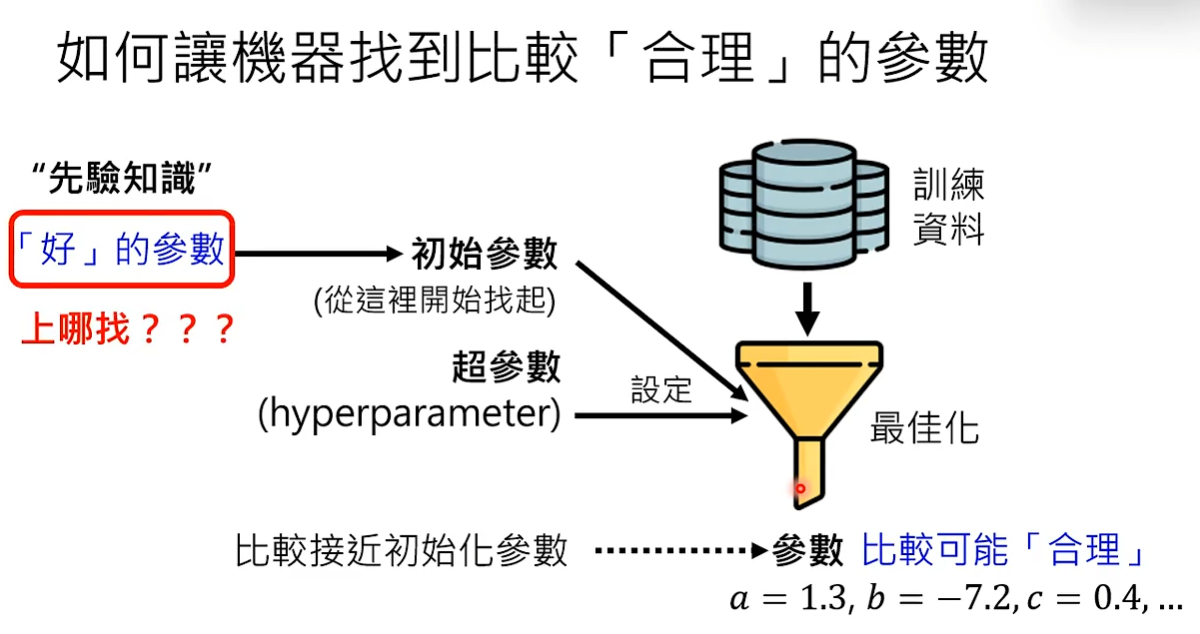
在最佳化之前,除了要设定超参数以外还要设定初始参数。 设定初始参数以后最终训练出来的参数就有可能与初始参数比较接近,因为最佳化的演算法会从初始参数找起,找到符合训练资料的参数。但因为也不知道初始参数是什么,所以只好随机产生初始参数,也就是说训练时的初始参数是掷色子生产的。这种最佳化的方法称为train from scratch。
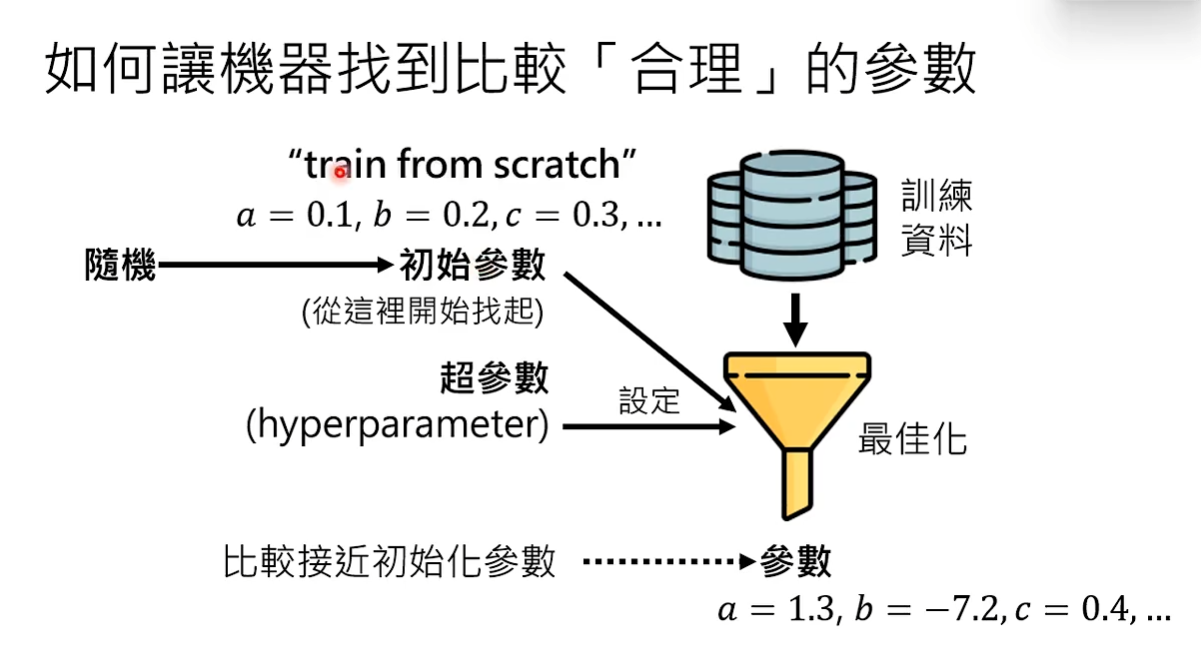
但是如果能设置好的初始参数,离符合训练资料的参数比较接近,最佳化产生的参数就可能更加合理。好的初始参数就是给模型的先验知识。
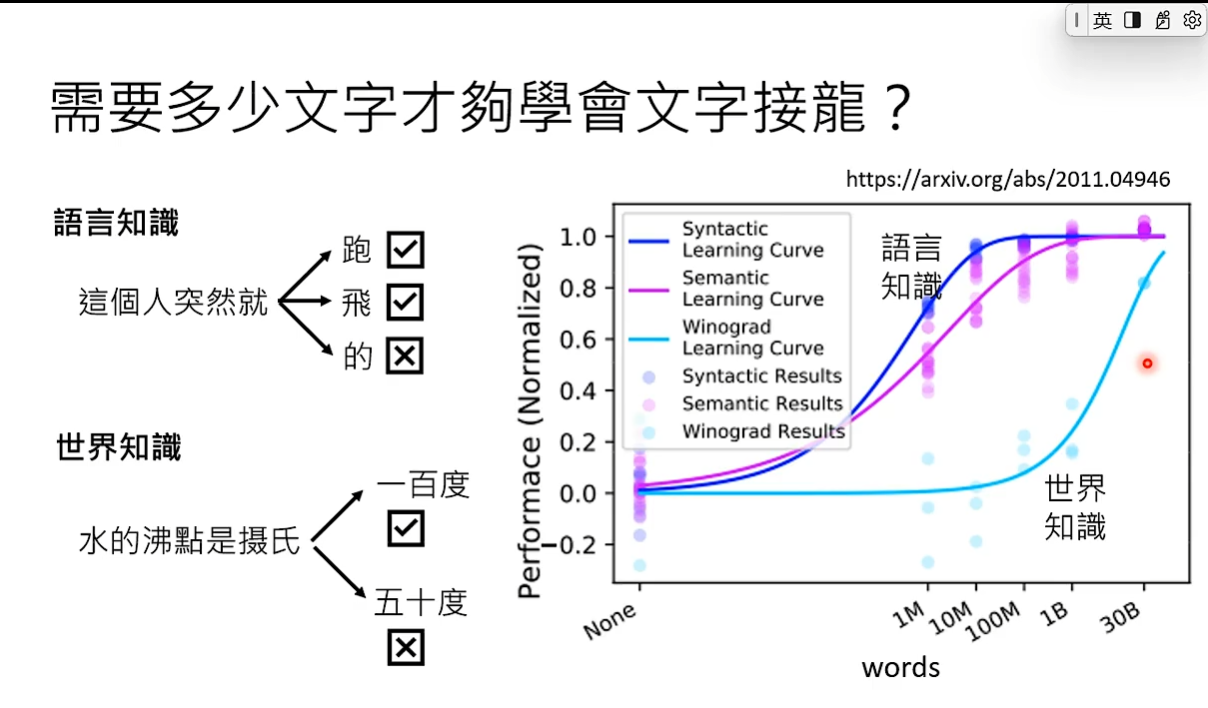
有1亿个词汇就足够使模型学会语言知识,但想要正确做接龙光知道语言的语法还不够,还需要世界知识。 根据论文,就算搜集的资料量有300亿个文字,还是不够让模型学会世界知识。因为世界知识分很多层次,比如对于小学生水的沸点是100摄氏度,但实际上水的沸点会随气压变化,所以需要非常大量的资料才能让模型学会世界知识。
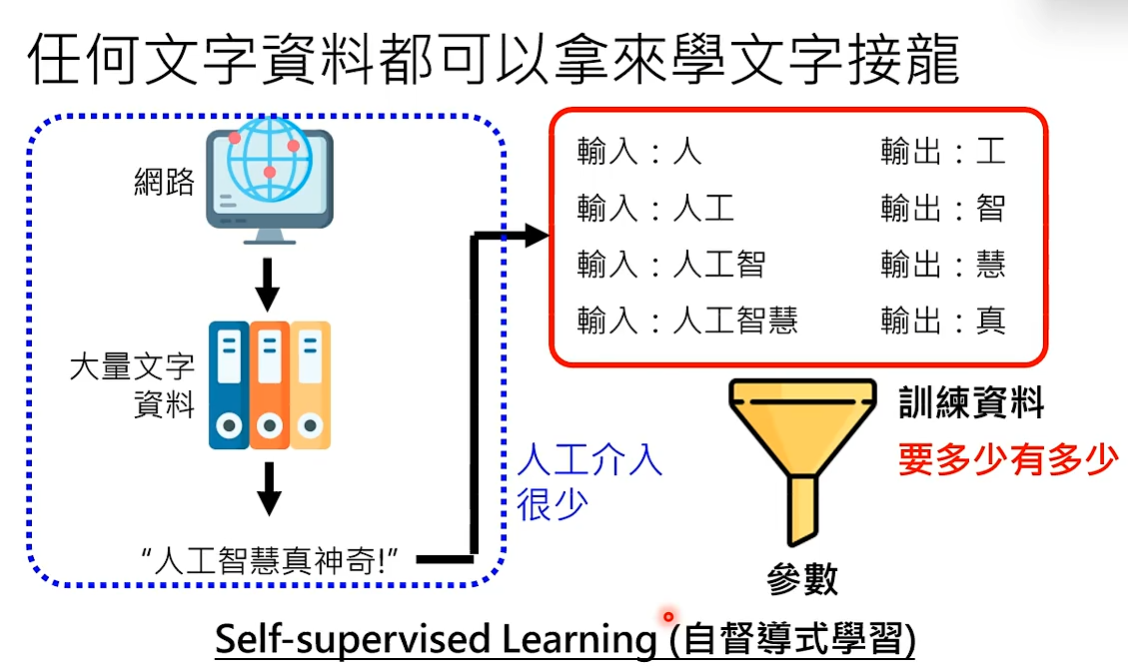
从哪找大量的文字资料呢?今天最常使用的来源就是网络,有无穷无尽的网页,无穷无尽的文字。 从网络上找文字资料训练的过程人工的介入非常少,这种训练方式称为自导式学习。
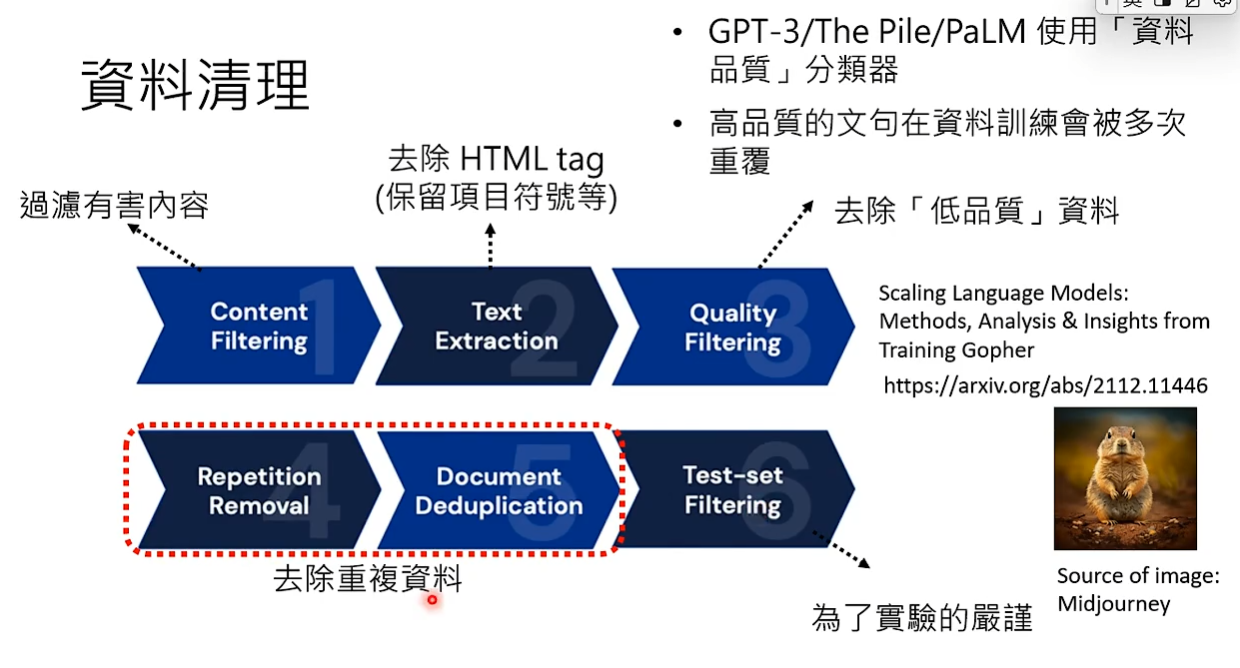
从网上爬下来的资料也需要做一些处理。
也不是任何资料都能拿来做文字接龙,可能也会遇到一些法律问题。
当模型大到一定程度,再大下去模型的能力也不会有明显的提升,此时就需要人工的介入。 因为模型虽然从网络上学习了很多资料,但他们根本不知道要怎样回答人类的问题。

HW4成为AI催眠大师¶

code:https://colab.research.google.com/drive/16JzVN_Mu4mJfyHQpQEuDx1q6jI-cAnEl?hl=zh-tw#scrollTo=dk-L0dvg9Q-y&uniqifier=1
编辑于2025年8月23日