生成式人工智能导论¶
大语言模型修炼史,第二阶段:名师指点,发挥潜力¶
Instruction Fine-tuning:人类老师提供一些指令,机器学习怎么按照这些指令来做正确的回应。 训练资料要耗费大量的人力才能取得,这种产生资料的方式叫做资料标注。通过耗费大量人力产生的资料训练出来的模型,这个训练过程就叫做督导式学习。

为什么要标注哪些资料是人类讲的,哪些资料是AI讲的? 因为使用者输入不同的句子,AI的回复就会不一样。

为什么不第一阶段就用人类老师教? 因为人类老师能提供的标注资料非常有限,只从人类老师学是不够的。
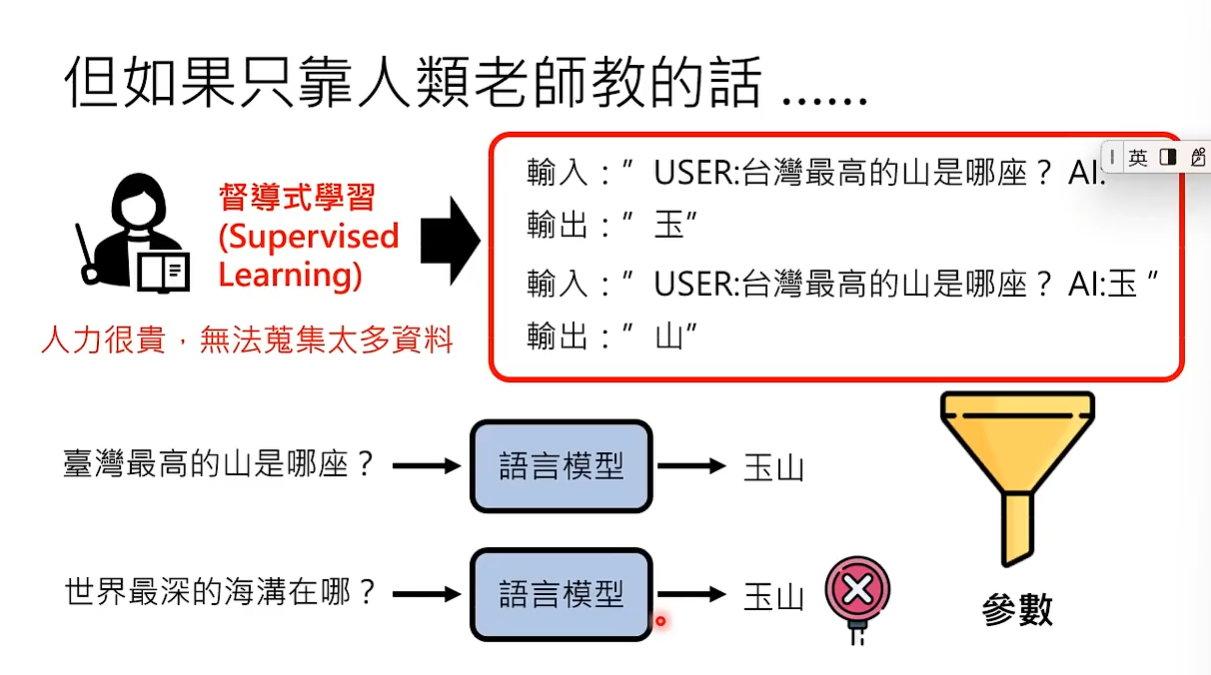
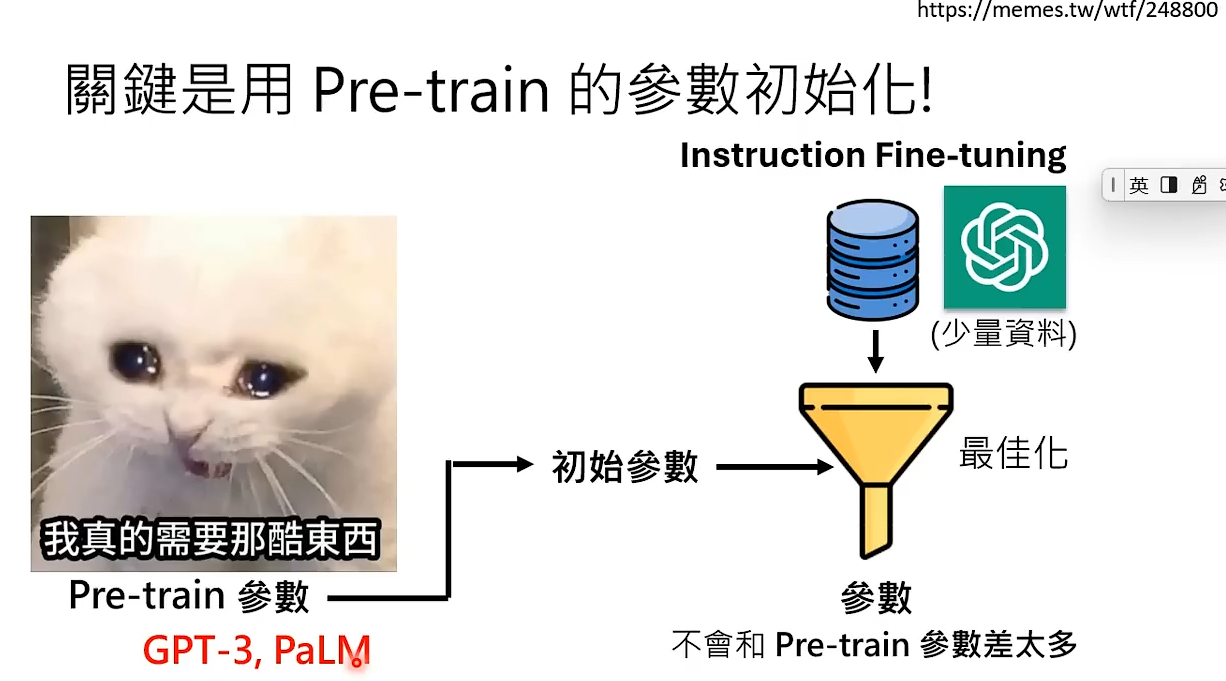
使用第一阶段得到的参数作为第二阶段的初始参数是关键。 如果模型训练出的参数不合理,往往有两种解决方式。一是堆训练资料,但第二阶段人类标注的训练资料是非常稀少的,所以只能找一组较好的初始参数。可以把第一阶段模型通过网络上大量的文字资料训练出来的参数作为第二阶段的初始参数。所以第二阶段训练出的参数不会与第一阶段差太多,instruction fine-tuning中的fine-tuning就意味着回调,代表第二阶段是第一阶段参数的回调。如果将用人类标注的资料学习的过程称为真正的学习,那么通过网络爬出来的资料学习的过程就称为预训练pre-train。
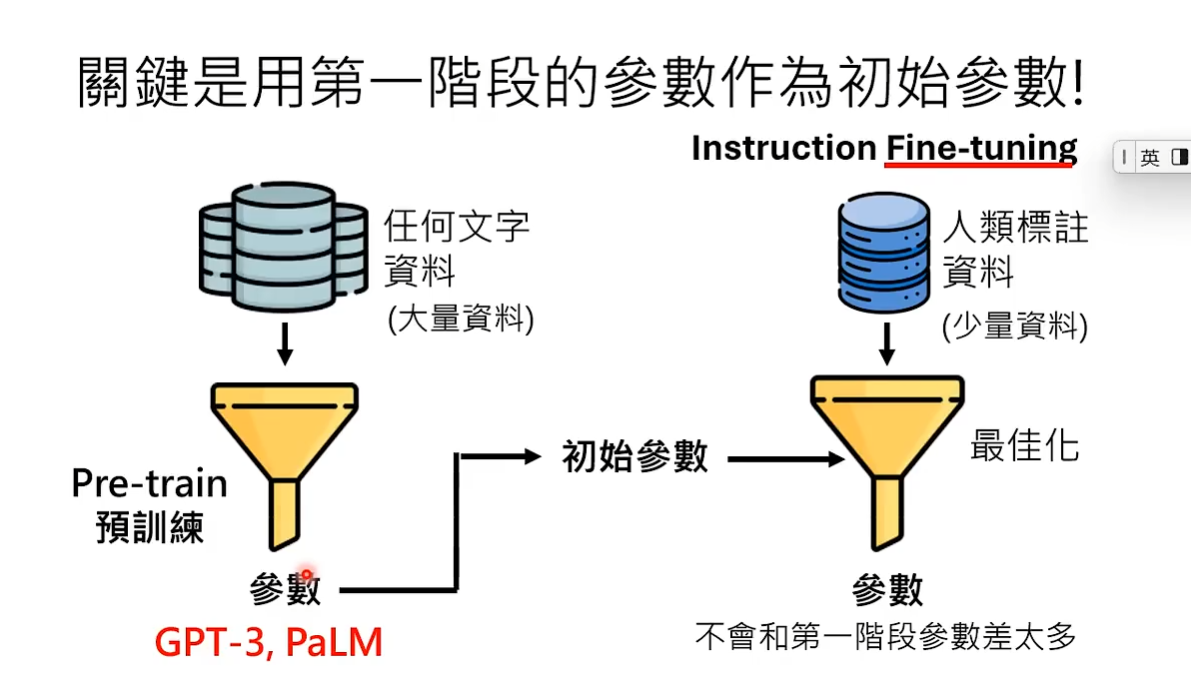
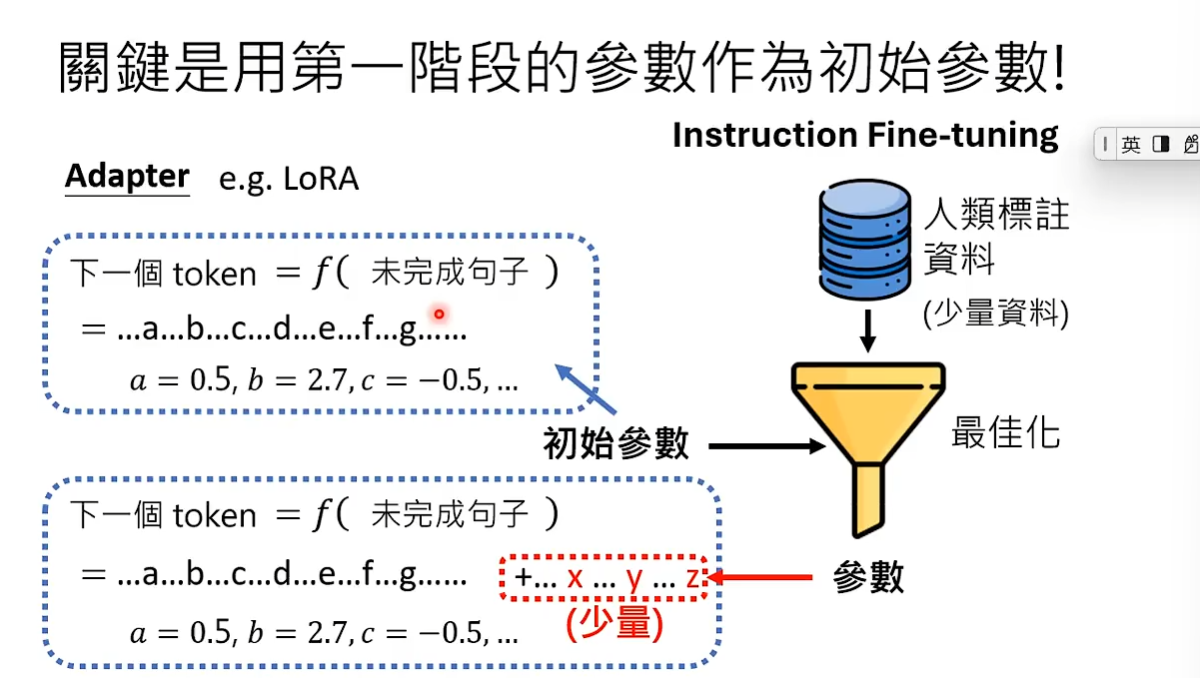
如果担心训练出来的参数与初始参数很不一样,可以用一个小技巧Adapter。 LORA就是Adapter的一种。Adapter就是将最佳化训练出来的参数作为初始参数的补充,只不过参数的量相比于初始参数非常的小,这样保证了初始参数不会被改变,也可以减少所需的运算量。Adapter有非常多种方式,本节课不做过多讨论。
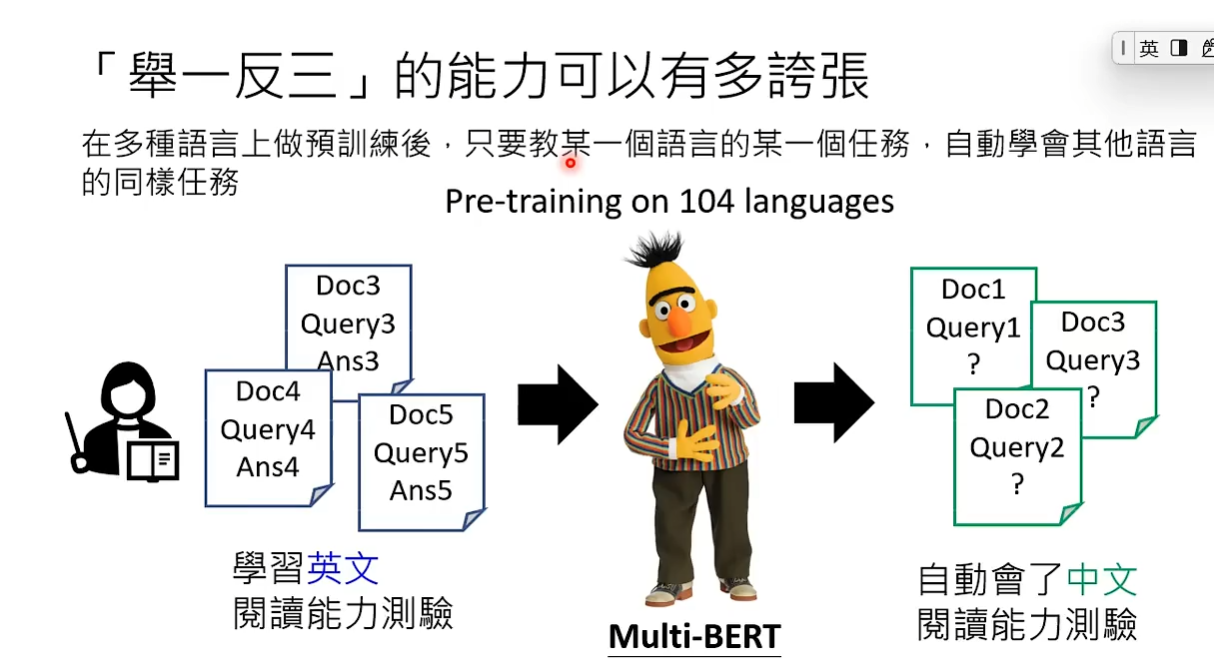
因为pre-train时看过非常大量的资料,所以用来做第二阶段的初始参数会更加准确。 在此基础上做最佳化之后,模型可能会有非常好的举一反三的能力。 举一反三例如教一个模型某一种语言的任务,他能自动学会其他语言的同样任务。
Fine-tuning的路线分成了两条。
1.打造一堆专才:比如训练一个翻译的模型,只提供翻译的资料,不教其他的事情。再训练一个修改的模型,只提供语法修正的资料。
2.直接打造一个通才:收集一大堆标注资料,涵盖了各式各样的任务。之前的训练方法是,虽然没有办法搜集到所有任务的资料,但可以一个一个任务的教语言模型。为了防止模型学了新的任务忘了旧的任务,可以使模型复习学过的任务,详情参考此论文:https://arxiv.org/abs/1909.03329v2。 后来各式各样的模型都开始走通才路线。
Instruction Fine-tuning是画龙点睛,不需要大量的资料。 虽然它不需要太多资料,但也不是每个人都能做,因为你没有高品质的资料,你不是open AI的工程师。但是我们可以对GPT做逆向工程,知道GPT用了什么Instruction Fine-tuning的资料。 此时我们有可以做Instruction Fine-tuning的资料了,很多小团队都是通过对GPT做逆向工程来获取资料的。

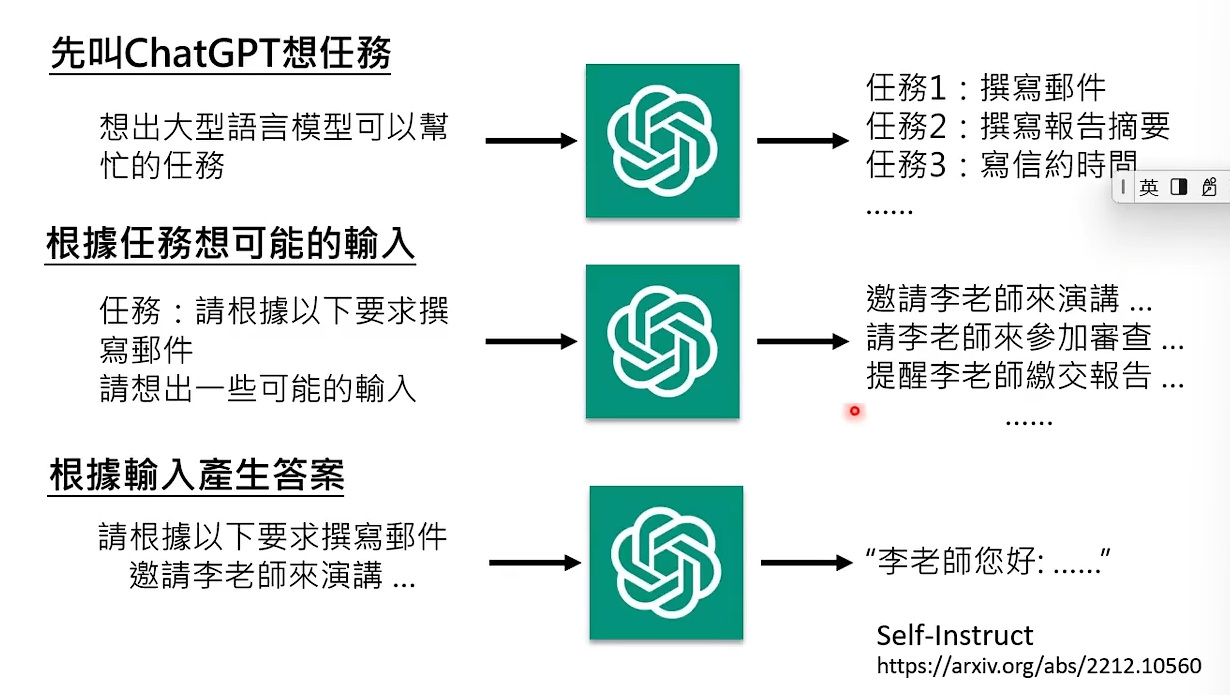
虽然我们通过逆向工程获得了少部分资料但还是不能做Instruction Fine-tuning,因为我们没有pre-train的参数。
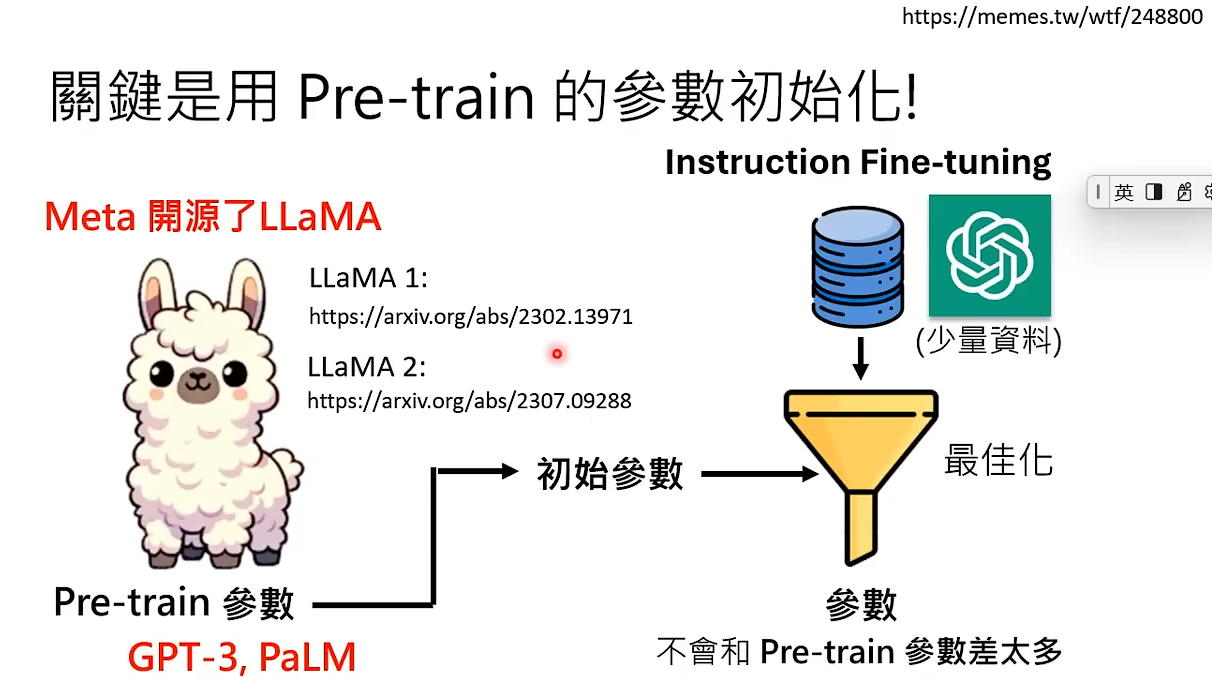
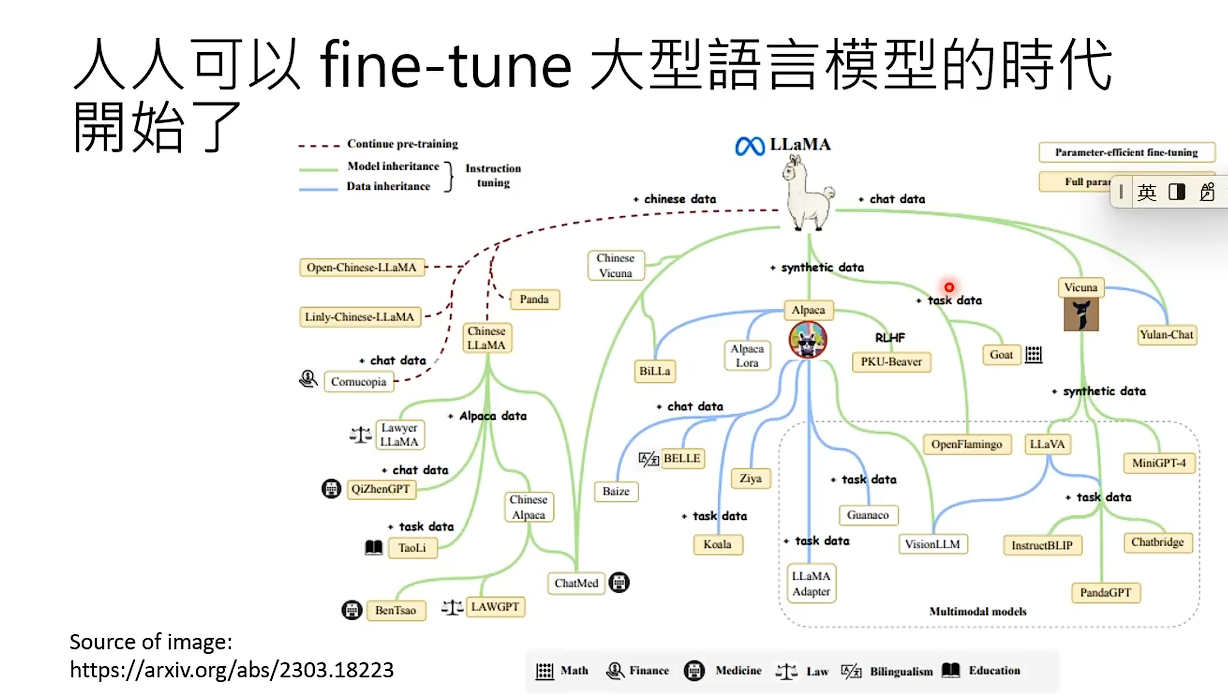
直到有一天,Meta开源了LLaMA。我们可以拿LLaMA作为我们的初始参数来打造我们自己的模型。 开源不久,美国的一些高校就通过从GPT获取的资料与从LLaMA获取的初始参数打造了自己的模型。真可谓,旧时王谢堂前燕,飞入寻常百姓家。每个人都可以训练自己的大型语言模型。

编辑于2025年8月25日